
파이썬 (Python) 데이터프레임과 loc, index의 관계
지난 시간에 다루었던 loc의 사용법이 기억나는가? 기억이 나지 않는다면 다시 한번 보고 오길 바란다.
아무튼 loc 활용 방법을 기억하면서 loc를 이용하여 데이터를 추가하거나 수정하는 경우 발생할 수 있는 문제점에 대하여 살펴보도록 하자. loc의 경우 기준 index를 기준으로 데이터에 접근한다. 앞서 예제에서는 인덱스를 지정하지 않았는데, 그 경우 자동으로 인덱스가 생성되는 것을 확인하였다.
이번에는 인덱스를 직접 지정하여 엑셀파일을 열어보겠다. 그리고 그 과정에서 인덱스가 정렬되지 않았을 경우 어떤 문제가 발생하는지 다양한 케이스를 살펴보도록 하자.
데이터 프레임에서는 인덱스의 개념이 매우 중요하다. loc뿐만 아니라 iloc 까지 다룰려면 이 개념을 이해하고 넘어가는 것이 좋다.
파이썬 (Python) 데이터프레임 loc를 이용한 행(Row) 삽입
데이터프레임에서 loc를 활용하는 방법을 다시 한번 복습해보자.
새로운 엑셀 파일을 다운로드 받아서 사용할 것이다.
sample2.xlsx
ps1200님이 공유한 문서를 확인하세요.
mybox.naver.com
위 링크에서 예제파일을 다운로드 받도록 하자. 파일을 열어보면 아래와 같이 데이터가 들어가 있을 것이다.
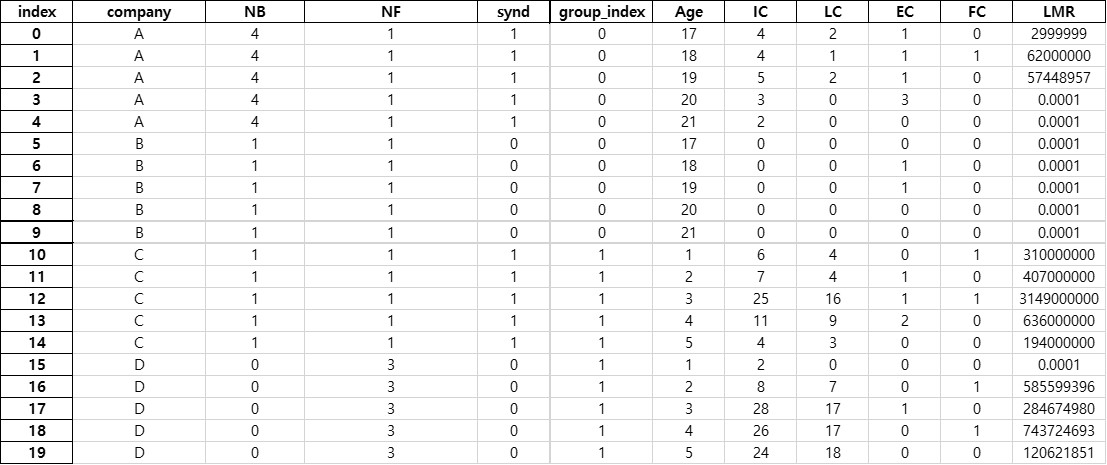
총 20개의 행이 들어 있는 엑셀파일이다. 지난번과 달리 index행이 존재한다.
이 엑셀 파일을 데이터프레임으로 바꾸어 보자. 이번에는 인덱스를 지정해 줄것이다.
import pandas as pd
df = pd.read_excel("sample2.xlsx",engine="openpyxl",na_values=" ", index_col=0)
print(df)
위 코드를 보면 지난번과 조금 크게 다르지 않는데, 마지막에 index_col =0 이라는 인자가 들어가 있는 것을 알 수 있다.
즉 지난 예제와 달리 인덱스 컬럼을 0번 컬럼으로 지정해준것이다.

그래서 이 코드를 실행해보면 아래와 같이 인덱스 열이 생긴것을 알 수 있다.

하지만 화면에 보이는 index는 데이터프레임의 열이 아니라 인덱스 그 자체이다. 무슨말인지 헷갈린다면 df.shape을 통하여 행열의 개수를 확인해보자.
import pandas as pd
df = pd.read_excel("sample2.xlsx",engine="openpyxl",na_values=" ", index_col=0)
print(df)
print(df.shape)
결과는 20개 행, 11개의 열로 나온다. 위에서 열의 개수를 세어보면 11개인것을 알 수 있다.
이말인즉, 인덱스는 데이터프레임에서 행을 처리하기 위한 기준과 같은 개념이지 열은 아니라는 것이다.
조금 더 자세히 알아보기 위해서 한줄 더 추가해서 출력해보자.
import pandas as pd
df = pd.read_excel("sample2.xlsx",engine="openpyxl",na_values=" ", index_col=0)
print(df)
print(df.shape)
print(df.info())
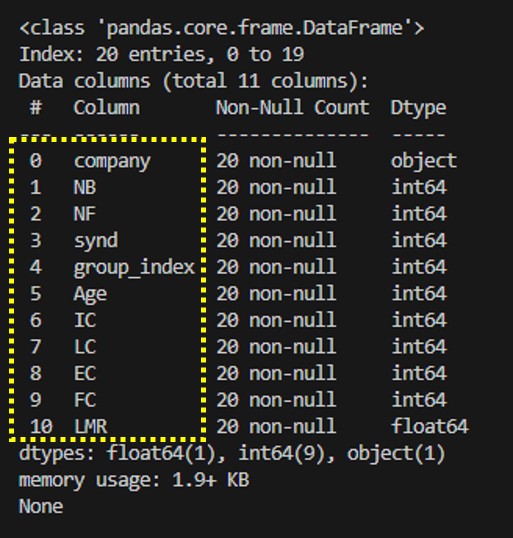
데이터프레임에 대한 기본적인 정보를 제공해준다. 열의 이름과 인덱스, 데이터 수, 데이터타입 등 다양한 정보를 보여준다. 데이터프레임의 구조를 확인할때 많이 사용한다.
여기에서는 index는 열로 나오지 않는것을 알 수 있다.
loc를 설명하는데 왜 계속 index를 이야기하냐하면 loc의 경우 index를 기준으로 처리하기 때문에 index의 개념을 잘 이해해야 하기 때문이다. 이해가 되었으면 loc이야기를 계속 해보겠다.
데이터프레임에서 loc는 index 값을 기준으로 데이터를 수정, 삽입, 삭제가 가능하다. 하나하나 테스트 해보자.
파이썬 (Python) 데이터프레임 loc를 이용한 행(Row) 데이터 수정
먼저 index를 활용하여 행과 행 사이에 새로운 데이터를 추가해보자. 아래의 사진 처럼 10번과 11번 행 사이에 새로운 행을 추가해 볼 것이다.

어...막상 하려고 자료를 준비하다보니 안된다 ㅜㅜ 될줄 알았는데 안된다. 미안하다.
좀더 고민해보고 다시 포스팅 할 수 있으면 하도록 하겠다.
그냥 제일 마지막에 행을 추가해보자 ㅡ.ㅡ... 현재 인덱스 기준 19번까지 있으니 20번을 인덱스를 새롭게 추가해보겠다.
import pandas as pd
df = pd.read_excel("sample2.xlsx",engine="openpyxl",na_values=" ", index_col=0)
df.loc[20] = ["새로운 데이터 추가", 0,0,0,0,0,0,0,0,0,0.001]
print(df)
마지막에 데이터가 잘 들어간것을 확인할 수 있다. 첫번째 열의 값을 길게 입력했기때문에 옆으로 밀려나긴 했지만 정상적으로 들어간 것이니 걱정하지 말자. 어짜피 나중에 다시 엑셀파일로 변환해서 확인해 볼것이다.
여기서 하나 확인하고 넘어갈 것은 loc로 행을 추가할때 리스트를 만들어서 리스트안에 열의 수만큼 데이터를 넣어줘야 한다. 그리고 데이터는 열의 데이터타입과 일치해야 한다.
앞서 df.info()를 출력해보면 데이터프레임의 정보가 나온것을 기억하는가? 데이터프레임의 행, 열 수, 타입 등등 정보를 확인할 수 있다. 다시한번 출력해보자.

Dtype를 확인해보면 object, int64, float64로 이루어진것을 알 수있다. object는 문자와 숫자가 같이 포함된것으로 그냥 string 이라고 생각하면 된다.
그래서 리스트를 만들어서 넣어줄때도 데이터타입에 맞게 넣어줘야한다. 이렇게..

그럼 이미 존재하는 인덱스를 지정하면 어떻게 되는가? 해당 인덱스의 행 값이 변경된다.
import pandas as pd
df = pd.read_excel("sample2.xlsx",engine="openpyxl",na_values=" ", index_col=0)
df.loc[20] = ["새로운 데이터 추가", 0,0,0,0,0,0,0,0,0,0.001]
df.loc[10] = ["인덱스 변경", 0,0,0,0,0,0,0,0,0,0.001]
print(df)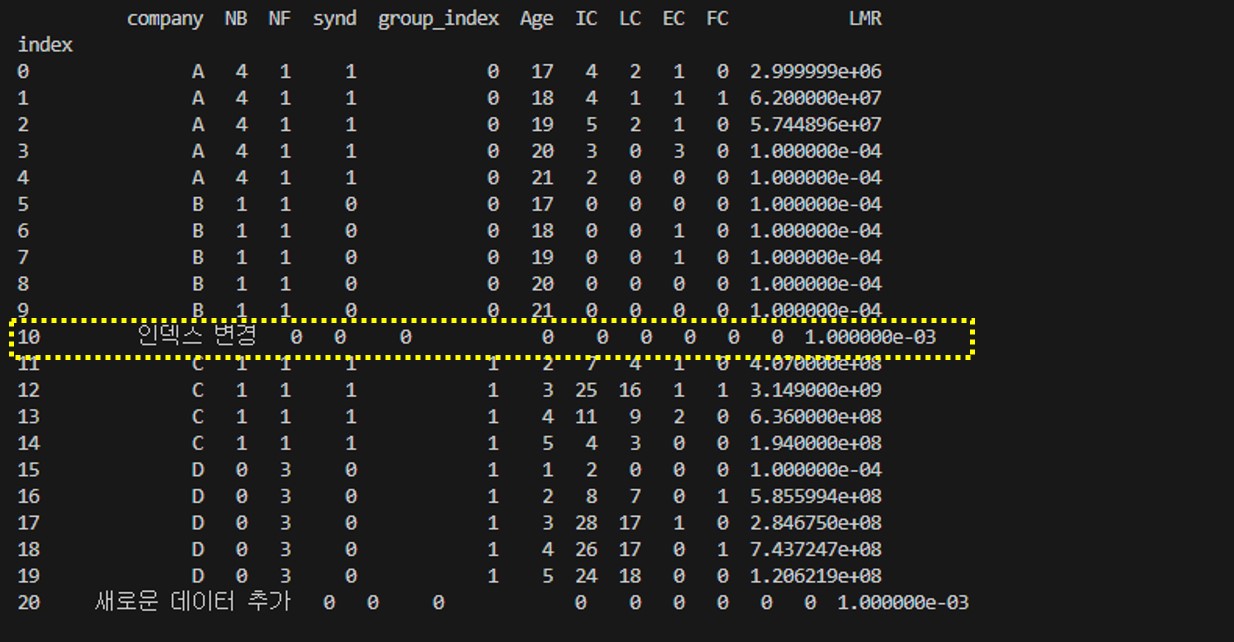
인덱스 10번 행의 값이 바뀐것을 알 수 있다. loc는 이렇게 인덱스를 기준으로 접근하는 방식이다.
행 전체의 값을 변경하는게 아니라 하나의 열 값만 바꿀려면 어떻게 해야할까?
loc로 인덱스 번호와 열의 이름을 지정하면된다.
import pandas as pd
df = pd.read_excel("sample2.xlsx",engine="openpyxl",na_values=" ", index_col=0)
df.loc[20] = ["새로운 데이터 추가", 0,0,0,0,0,0,0,0,0,0.001]
df.loc[10] = ["인덱스 변경", 0,0,0,0,0,0,0,0,0,0.001]
df.loc[15,"Age"] = 99
print(df)
15번 행의 Age 열의 값을 99로 바꾸어 보겠다.

잘 변경된것을 확인할 수 있다.
파이썬 (Python) 데이터프레임 index가 정렬되지 않았을 때 나타나는 문제점
마지막으로 정렬되지 않은 인덱스가 있는경우를 가정해보자. 데이터프레임을 자르고 붙이고 하다보면 인덱스가 종종 꼬일때가 있다. 아래의 파일을 다운받아 열어보자.
sample3.xlsx
ps1200님이 공유한 문서를 확인하세요.
mybox.naver.com

엑셀파일의 index 열을 확인해보면 값이 순차적으로 들어가 있지 않음을 알 수 있다. 이 엑셀파일을 그대로 데이터프레임으로 변환시켜보자.
import pandas as pd
df = pd.read_excel("sample3.xlsx",engine="openpyxl",na_values=" ", index_col=0)
print(df)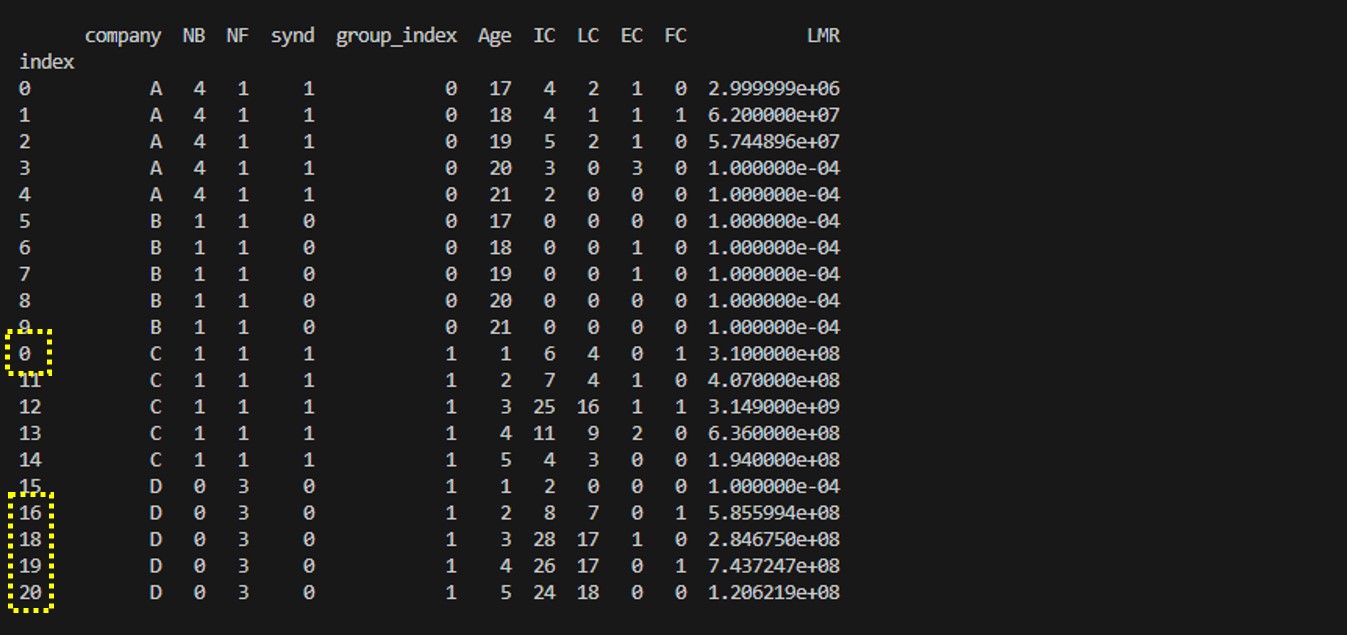
첫 번째 열을 인덱스로 지정해주고 데이터프레임으로 변환시켜보면 엑셀파일처럼 인덱스가 순차적으로 정렬되지 않은채 그대로 데이터프레임으로 변환되었음을 알 수있다.
이렇게 되면 가끔 문제가 생긴다. 지금은 행 자체가 몇개 안되기때문에 쉽게 발견되지만 데이터가 10만개 이상 들어가 있다고 생각해보자. 발견하기 어려울 것이다.
또한 for 문을 이용하여 데이터를 삽입하거나 수정하고자 할때 에러가 인덱스 때문에 에러가 발생한다.
이런 경우 값을 수정하면 어떻게 되는지 테스트해보자.
먼저 0번 인덱스를 변경해보겠다. 데이터프레임 기준 인덱스 0은 현재 2개이다.

아래와 같이 코드를 넣고 실행해보자. 코드는 0번 인덱스의 company 열의 값을 "인덱스 수정"으로 변경하라는 코드이다.
import pandas as pd
df = pd.read_excel("sample3.xlsx",engine="openpyxl",na_values=" ", index_col=0)
df.loc[0, 'company'] ="인덱스 수정"
print(df)
인덱스가 0인 두 행모두 값이 바뀌었음을 알 수 있다. 파이썬에서는 에러가 발생하진 않았지만 데이터를 다루는 입장에서는 에러일 것이다.
그다음은 17번 인덱스를 추가해보자. 현재 데이터프레임에서 17번 인덱스가 비워져 있는것을 알 수 있다. loc를 통하여 17번 인덱스에 값을 넣어보자.

import pandas as pd
df = pd.read_excel("sample3.xlsx",engine="openpyxl",na_values=" ", index_col=0)
df.loc[0, 'company'] ="인덱스 수정"
df.loc[17] =["17번 인덱스 추가", 0,0,0,0,0,0,0,0,0,0.001]
print(df)
위 코드를 실행해보자. 데이터는 16번과 17번 행 사이에 들어가 있을까?
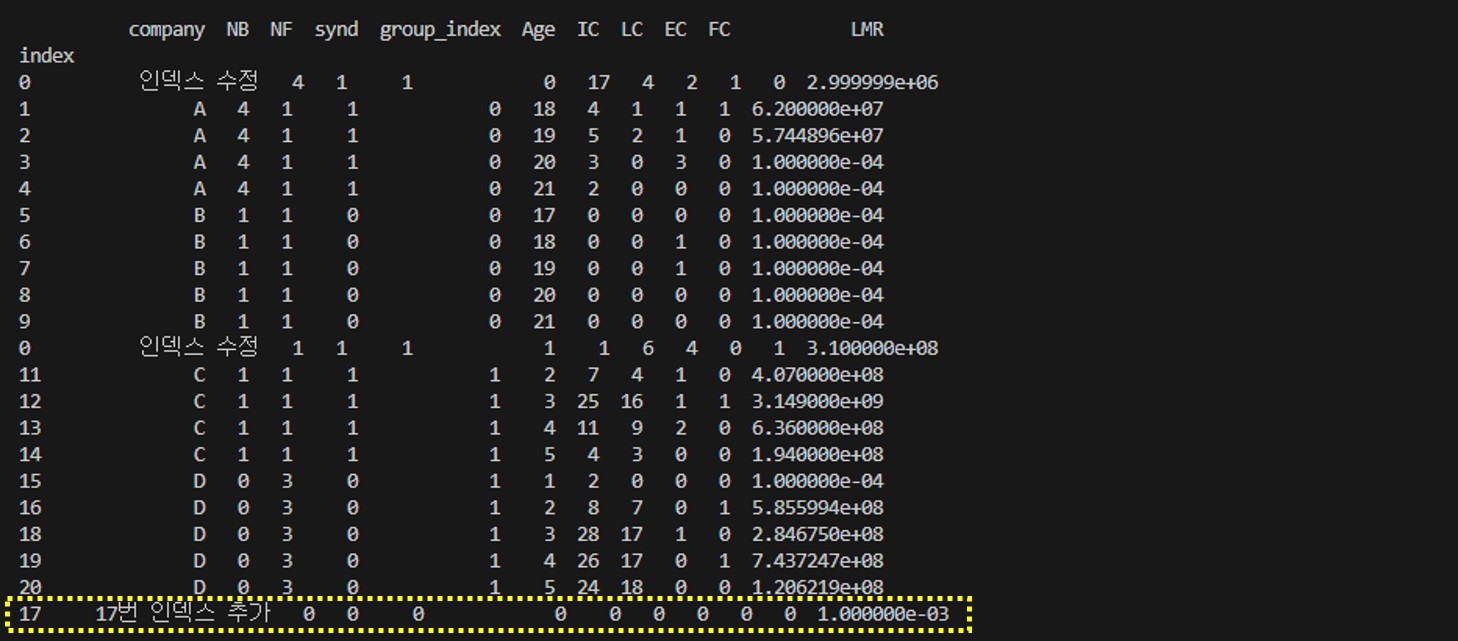
17번 인덱스를 추가했지만 인덱스의 위치는 젤 마지막에 들어가 있다. 인덱스는 17인데도 말이다.
이렇듯 데이터프레임에서 인덱스는 항상 순차적으로 정렬되는 것은 아니다. 데이터를 전처리하는 과정에서 인덱스가 꼬일 수 있다는 것을 항상 명심해야 한다.
눈에 보이지는 않지만 항상 순차적으로 정렬되는 기준은 따로있다. 그것을 활용하는것이 바로 iloc 이다.
오늘 loc만 다루고 다음에 iloc를 다루도록 하겠다.
'파이썬 > 파이썬 데이터프레임' 카테고리의 다른 글
| 파이썬 (Python) Dataframe 기초 강좌 #6 - iloc 누적 합 구하기 (0) | 2024.09.27 |
|---|---|
| 파이썬 (Python) Dataframe 기초 강좌 #5 - loc와 iloc 사용법과 차이점 (0) | 2024.09.26 |
| 파이썬 (Python) Dataframe 기초 강좌 #4 - 데이터프레임과 index (0) | 2024.09.19 |
| 파이썬 (Python) 데이터프레임 기초 강좌#2 - 행과 열, 데이터 추가하는 방법 (0) | 2024.09.08 |
| 파이썬 (Python) 데이터프레임 기초 강좌 #1 -엑셀 파일 데이터프레임 변환 (0) | 2024.09.05 |



