
지난 편에서 인덱스의 중요성과 인덱스를 활용하는 방법에 대하여 알아보았다.
이번에는 인덱스를 초기화 및 엑셀 파일로 저장시 인덱스를 없애는 방법 등에 대하여 알아보겠다.
데이터프레임(Dataframe)과 인덱스 활용 방법
데이터 프레임을 다루다보면 인덱스를 활용해야 하는 경우가 종종 발생한다. 앞 포스팅에서는 loc() 활용하여 데이터를 다룰때 인덱스가 중요하다는 것을 확인 하였다.
오늘은 이 인덱스에 대하여 조금 더 알아보도록 하자.
지난 포스팅의 데이터를 그대로 불러와 보자. 파일이 없다면 아래의 링크로 들어가 다운로드 받길 바란다.
파이썬 (Python) 데이터프레임 기초 강좌 #3 - loc와 index의 이해
목차파이썬 (Python) 데이터프레임과 loc, index의 관계파이썬 (Python) 데이터프레임 loc를 이용한 행(Row) 삽입파이썬 (Python) 데이터프레임 loc를 이용한 행(Row) 데이터 수정파이썬 (Python) 데이터프레임 i
flex-link.co.kr
sample3.xlsx 파일을 열어보면 아래와 같이 데이터가 들어가 있을 것이다.
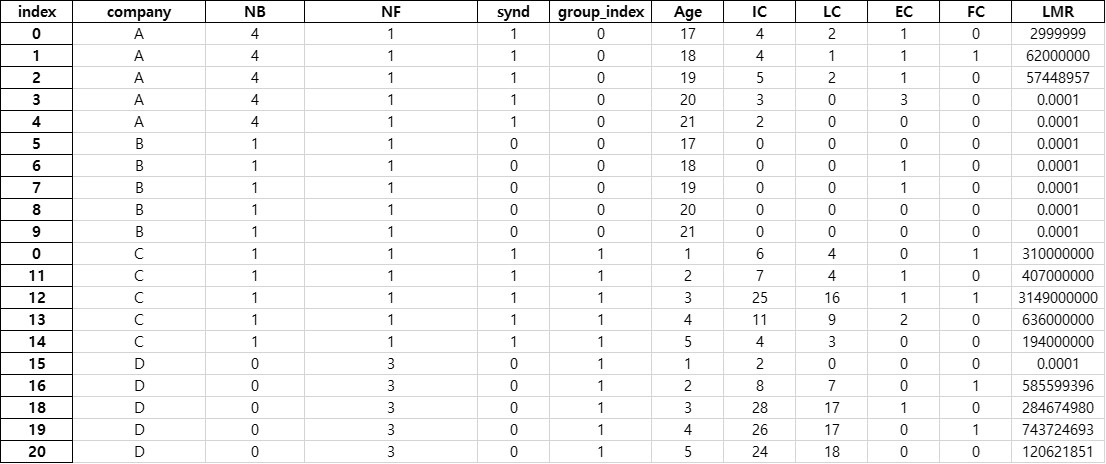
인덱스 열이 존재하며, 0~19까지 총 20개의 데이터가 들어가 있는데. 10번 행의 경우 인덱스가 0으로 되어있다.
복습할겸 데이터프레임으로 읽고 출력해보자.
import pandas as pd
df = pd.read_excel("sample3.xlsx", engine="openpyxl", na_values=" ", index_col=0)
print(df)

데이터를 다루다 보면 저렇게 인덱스가 꼬일때가 있다. 이제 이 인덱스를 바로 잡아보자.
파이썬 데이터프레임 (Dataframe) reset_index() 사용방법
인덱스를 재정렬하는 것은 생각보다 간단하다. 아래와 같이 코드를 추가해주자.
import pandas as pd
df = pd.read_excel("sample3.xlsx", engine="openpyxl", na_values=" ", index_col=0)
df = df.reset_index()
print(df)
3번째 코드가 바로 인덱스를 리셋하는 부분이다. 다만 이 코드는 리셋후 새로운 df에 넣어주었다.
출력된 결과를 살펴보면 인덱스가 제대로 정렬이 된것을 알 수 있다.
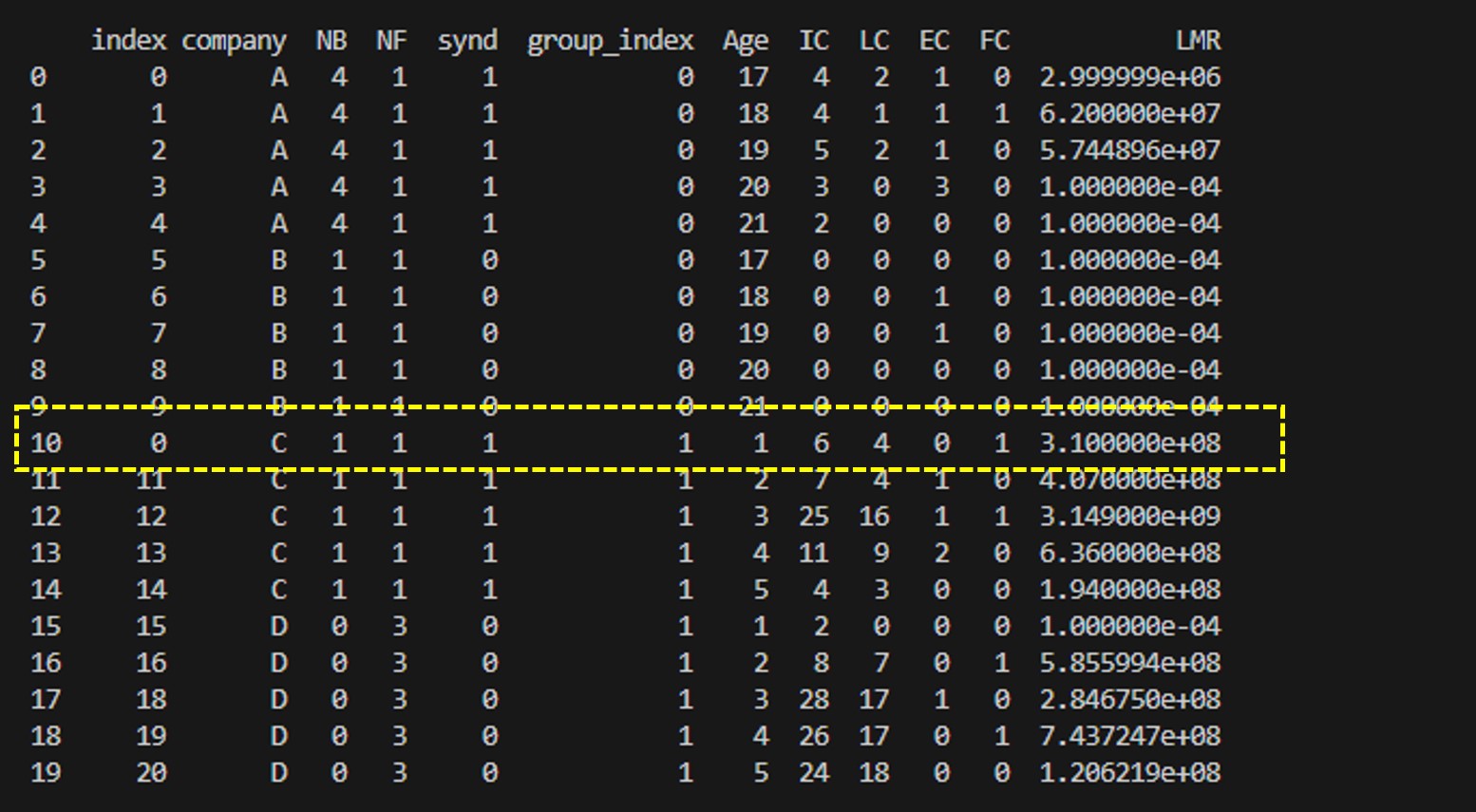
그런데 이상한점이 발견 되었다. 기존의 인덱스는 열로 바뀌었고, 새로운 인덱스가 추가된것이다.

엑셀 파일에 있던 index 행을 데이터프레임의 인덱스로 사용하였는데, 인덱스를 정렬하려고 reset_index()를 하고 새로운 df 변수에 넣어주는 순간 새로운 인덱스가 생겨버렸다.
그리고 기존의 인덱스는 index 라는 열로 변경된 것을 알 수 있다. df.info()를 이용하여 행과 열의 구조를 알아보자
import pandas as pd
df = pd.read_excel("sample3.xlsx", engine="openpyxl", na_values=" ", index_col=0)
df = df.reset_index()
print(df)
print(df.info())
인덱스가 열로 전환되어 총 12개의 열로 되어 있는 걸 알 수 있다. 이번에는 엑셀파일로 변경해보자.
import pandas as pd
df = pd.read_excel("sample3.xlsx", engine="openpyxl", na_values=" ", index_col=0)
df = df.reset_index()
print(df)
print(df.info())
df.to_excel("sample3-1.xlsx")
생성된 엑셀파일을 열어보면 새로운 열이 추가어 있는 것을 알 수 있다.
인덱스에 대하여 이해가 가는가? 저게 왜 생겼는지 이해가 필요하다.
새로운 인덱스가 생긴 이유는 바로 아래 코드 때문이다.
df = df.reset_index()
reset_index()의 경우 인덱스를 초기화하는 과정에서 기존의 인덱스를 남겨두고 새로운 인덱스를 생성하여 초기화 하기때문이다.
import pandas as pd
df = pd.read_excel("sample3.xlsx", engine="openpyxl", na_values=" ", index_col=0)
df_reset_index = df.reset_index()
print(df_reset_index)
print(df_reset_index.info())
df_reset_index.to_excel("sample3-2.xlsx")
데이터프레임 이름을 df_reset_index라고 만들어 넣어주었다. 이 df_reset_index를 출력해보자.
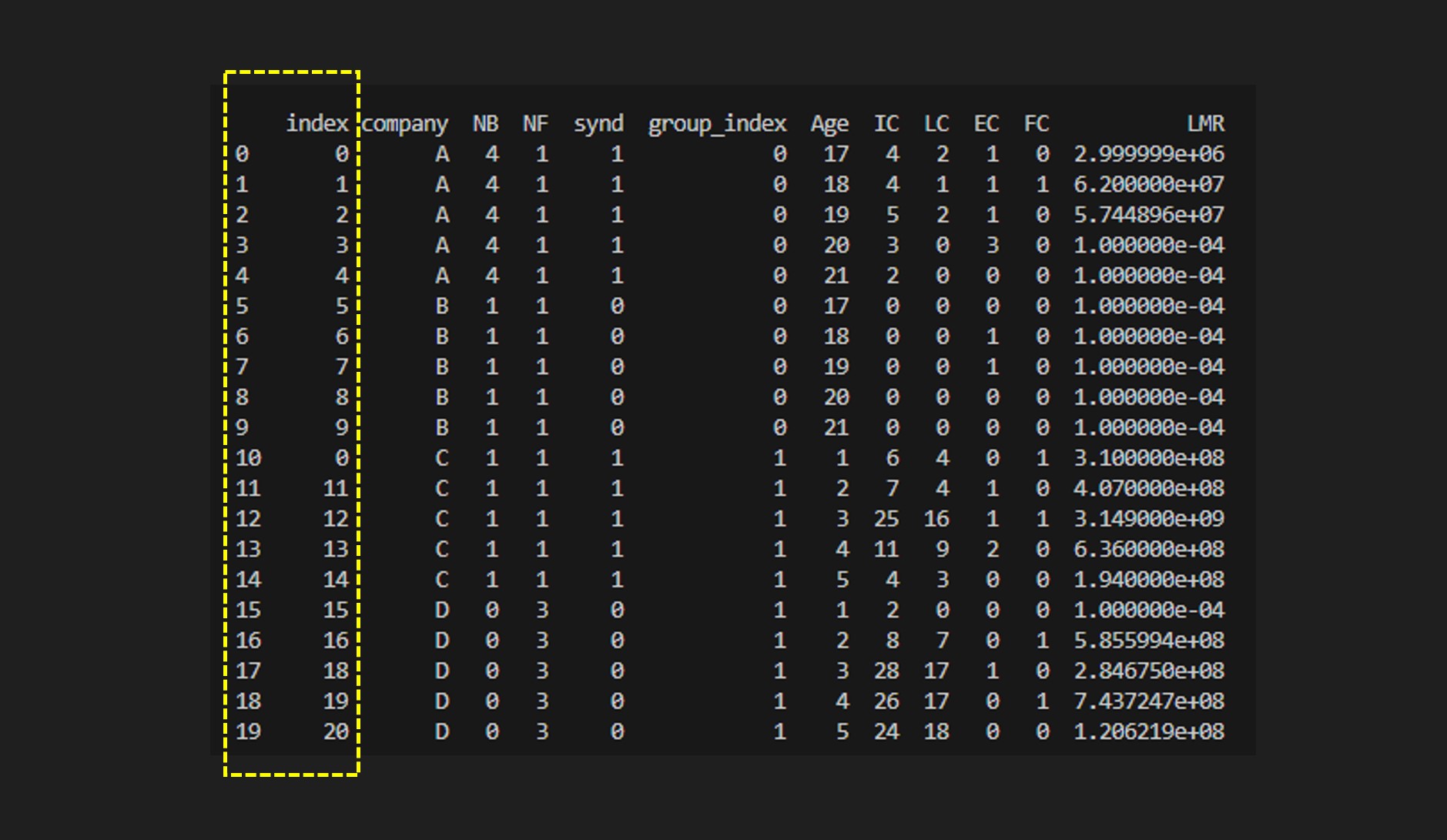
똑같은 결과임을 알 수 있다. 인덱스를 초기화하여 새로운 변수에 넣어줘도 똑같은 결과이다.
당연히 reset_index()를 수행하는 횟수만큼 인덱스가 생성되는것을 알 수 있다.
import pandas as pd
df = pd.read_excel("sample3.xlsx", engine="openpyxl", na_values=" ", index_col=0)
df_reset_index = df.reset_index()
df_reset_index2 = df_reset_index.reset_index()
print(df_reset_index2)
print(df_reset_index2.info())
df_reset_index2.to_excel("sample3-2.xlsx")
결과를 보면 또 새로운 인덱스가 생겼고, 기존의 인덱스는 level_0이라는 이름의 열로 전환 되었다.
생성된 엑셀파일을 열어봐도 비슷할 것이다.
그렇다면 새로운 인덱스가 생성되지 않도록 하는 방법은 없을까? 물론 있다.
바로 알애에서 알아보도록 하자.
파이썬 데이터프레임 (Dataframe) 기존 인덱스 삭제 및 이름 변경
새로운 인덱스가 생기지 않게 하는 방법은 간단하다. 기존의 인덱스를 삭제하라는 옵션을 주면된다.
drop=True를 옵션으로 줘보자.
import pandas as pd
df = pd.read_excel("sample3.xlsx", engine="openpyxl", na_values=" ", index_col=0)
df = df.reset_index(drop=True)
print(df)
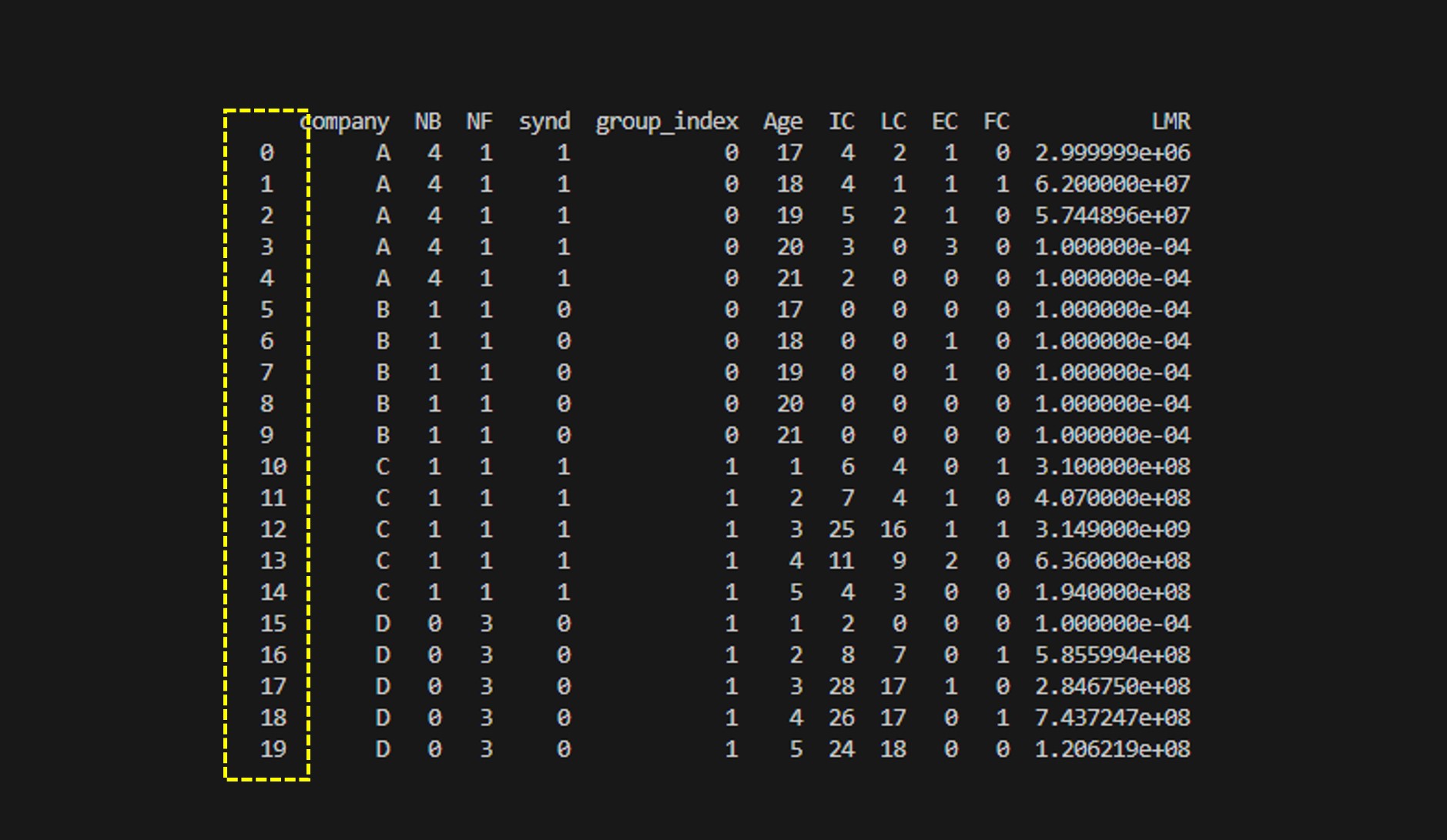
기존의 인덱스가 삭제되고 새로운 인덱스가 생성된것을 알 수 있다. 단 여전히 인덱스의 이름은 없는 상태이다
그럼 이름을 한번 지정해보자.
import pandas as pd
df = pd.read_excel("sample3.xlsx", engine="openpyxl", na_values=" ", index_col=0)
df = df.reset_index(drop=True)
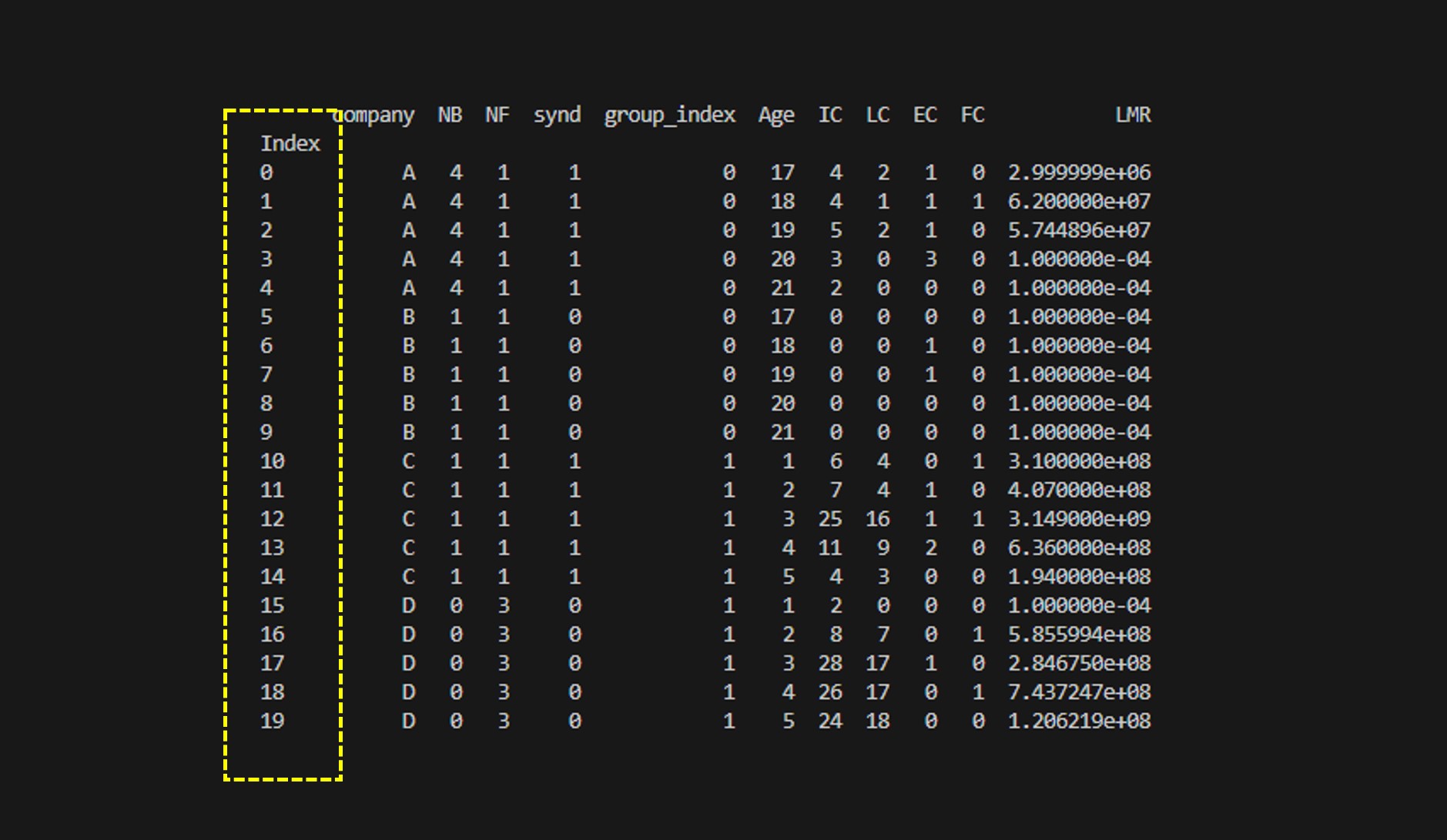
df.index.name="Index"
print(df)인덱스의 이름을 지정하는 것은 비교적 간단하고, 결과 역시 깔끔히 잘 반영된다
파이썬 데이터프레임 (Dataframe) sort_index() 인덱스 정렬
지난 포스팅에서 인덱스가 꼬여 뒤죽박죽된 데이터를 다룬적이 있었다.
임의로 아래와 같이 엑셀파일의 인덱스를 조금 수정하였다. 다들 직접 수정하고 진행해보길 바란다

순서가 뒤죽박죽 된것을 알 수 있다. 이제 이 파일을 데이터프레임으로 읽어보자.
import pandas as pd
df = pd.read_excel("sample4.xlsx", engine="openpyxl", na_values=" ", index_col=0)
print(df)
출력 결과 역시 엑셀파일과 동일하다. 이제 이 인덱스를 정렬해보자.
처음 방법처럼 reset_index()를 사용하여 정렬하는 방법이 있을 것이다. 그렇게 되면 현재 행은 그대로고 인덱스만 리셋되는 것을 알 수 있었다.
두번째 방법은 sort_index()를 사용할 것이다. 이것은 인덱스를 초기화하는것이 아니라 현재 상태에서 정렬하는 것이다.
import pandas as pd
df = pd.read_excel("sample4.xlsx", engine="openpyxl", na_values=" ", index_col=0)
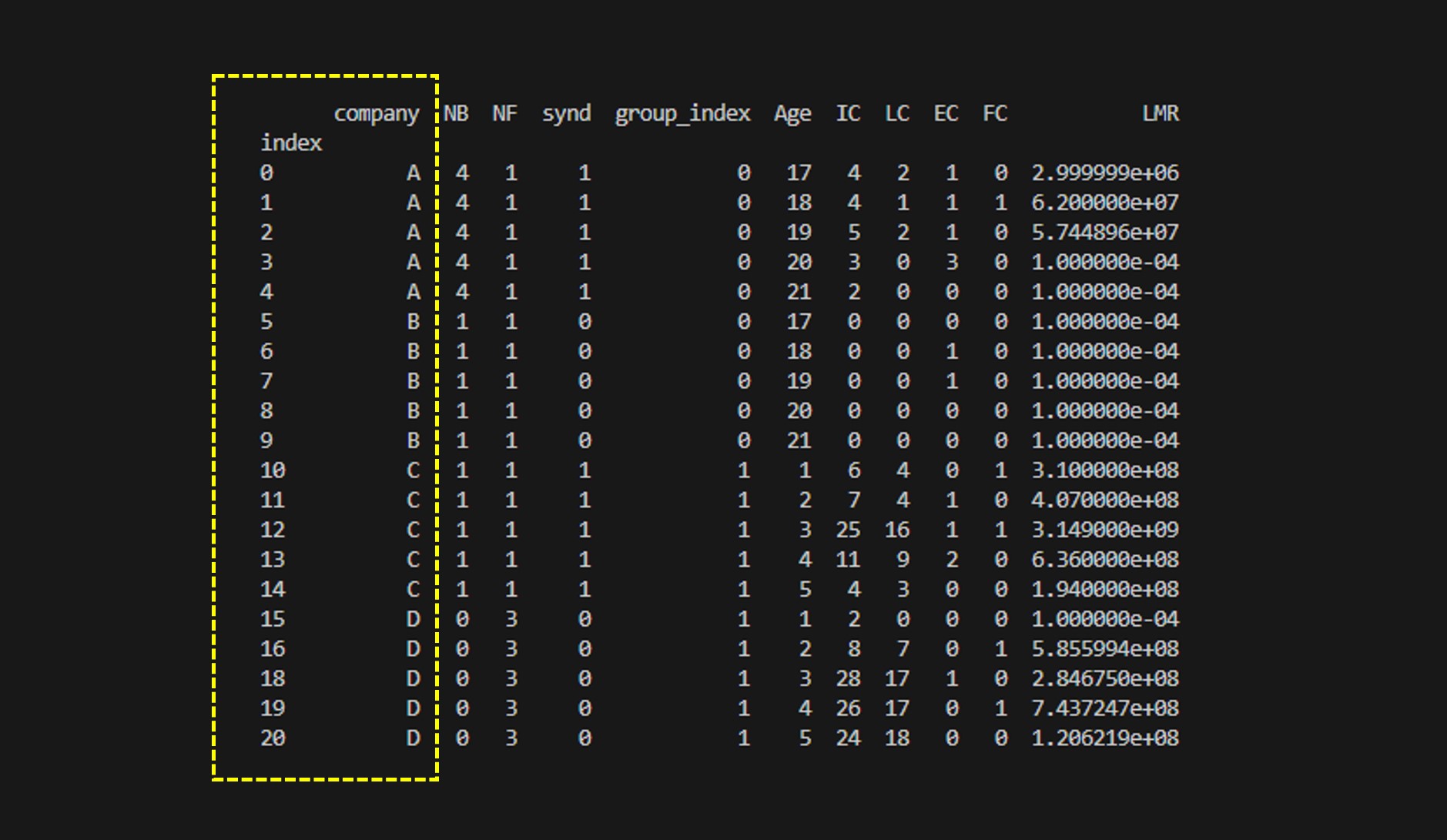
df = df.sort_index()
print(df)위와 같이 입력하고 실행해보자. 아래처럼 인덱스가 정렬된 것을 알 수 있다

그런데 reset_index()와 sort_index()가 어떤 차이인지 헷갈린다고?
그럼 옆에 있는 company 열과 같이 보면된다.
먼저 reset_index()를 적용한 경우이다. 인덱스는 리셋되었으나 행 데이터의 변화는 없다. company행을 보자. A, B, C, D가 섞여 있는 것을 알 수 있다.

sort_index() 결과를 보자. 인덱스도 정렬되어 있고, company도 A,B,C,D 순서로 정렬되어 있는것을 알 수 있다.
즉, 처음 데이터와 그대로 정렬이 되었다.
데이터프레임 (Dataframe) 인덱스 마무리
오늘은 인덱스에 대하여 조금 더 알아보았다. 우선 이정도만 알면 인덱스가 익숙하리라 생각된다.
헷갈리는 부분은 반드시 직접 코딩하고 결과를 살펴 보아야 한다.
다음 시간에는 loc와 iloc에 대하여 포스팅 해보겠다.
아 힘들다.ㅠㅠ
'파이썬 > 파이썬 데이터프레임' 카테고리의 다른 글
| 파이썬 (Python) Dataframe 기초 강좌 #6 - iloc 누적 합 구하기 (0) | 2024.09.27 |
|---|---|
| 파이썬 (Python) Dataframe 기초 강좌 #5 - loc와 iloc 사용법과 차이점 (0) | 2024.09.26 |
| 파이썬 (Python) 데이터프레임 기초 강좌 #3 - loc와 index의 이해 (0) | 2024.09.11 |
| 파이썬 (Python) 데이터프레임 기초 강좌#2 - 행과 열, 데이터 추가하는 방법 (0) | 2024.09.08 |
| 파이썬 (Python) 데이터프레임 기초 강좌 #1 -엑셀 파일 데이터프레임 변환 (0) | 2024.09.05 |



