
파이썬(Python) 데이터프레임과 판다스(Pandas), 엑셀
파이썬을 독학하면서 가장 어려웠던것이 데이터프레임(Dataframe)이었다. 이 글을 읽는 사람들도 역시 데이터프레임이 어려워서 읽고 있는 것이라 예상된다.
박사과정 동안 데이터프레임만 주구장창 만들고 사용하였지만 아직까지 헷갈려서 나도 다른 블로그를 찾아보며 개발하곤 했다. (사실 지금도 다른 블로그를 많이 참고한다). 개인적인 생각이지만 파이썬과 관련하여 모든 문법을 외울필요가 없다.
궁금한점이 있으면 검색만 하더라도 얼마든지 정보를 찾을 수있다. 특히 파이썬은 구글링만 하더라도 웬만큼 소스를 얻을 수 있다.
전문적인 개발자가 아니라면 구지 많은 문법을 외울필요가 있을까? 그냥 찾아보면서 해도 충분하다. 암튼 비개발자의 생각이니 참고만 하자.
아무튼 파이썬의 꽃은 데이터프레임이라고 해도 과언이 아닐정도로 데이터프레임의 활용도는 높다.
하지만 그만큼 어려운것도 사실이다.
구글링을 통하여 많은 글을 참고하면서 느끼고 배우고, 내것을 만들려고 노력하면서 알게된 노하우를 몇편의 시리즈로 글을 써볼까 한다.
복잡하고 어려운 단어는 최대한 피하고 내가 이해하는 대로 설명하도록 하겠다.
우선 데이터 프레임의 정의를 살펴보자.
데이터프레임이란?
데이터프레임(Data Frame)은 판다스에서 사용되는 가장 중요한 데이터 구조 중 하나예요. 우리가 공부할 때 노트에 정보를 정리하고, 각 정보를 표의 칸에 적어놓는 것처럼 데이터프레임은 컴퓨터로 정보를 정리하고 저장하는 도구예요. 데이터프레임은 행(가로줄)과 열(세로줄)로 이루어져 있어서, 이것을 사용하면 정보를 쉽게 정리하고 찾을 수 있어요.
출처 : 위키독스 https://wikidocs.net/220639
위키독스에서는 저렇게 설명한다.
하지만 내 생각은 이렇다
데이터 프레임은 파이썬용 엑셀이다
파이썬에서 사용할 수 있는 엑셀과 같다. 즉, 코드로 만드는 엑셀이라고 생각해보자. 마우스로 드래그하고, 셀을 클릭해서 값을 집어 넣는 마이크로소프트 엑셀이 아니라, 코딩으로 값을 넣는 엑셀이라 생각해보자.
엑셀이 있는데 왜 파이썬을 엑셀처럼 사용하지? 라고 생각할 수 있으나 사용해보면 느낄 수 있다. 엑셀보다 엄청 빠르고 간편하다는 것을....
아무튼 데이터 분석을 위해서, 특히 데이터 전처리를 위해서 데이터프레임만큼 편한것이 또 없다.
그래서 아무튼....데이터프레임은 파이썬에서 가장 중요한 부분이라 생각한다.
그러니까 꼭 제대로 공부해야 한다.
그럼 지금부터 파이선용 엑셀을 사용하기 위한 준비를 해보자.
파이썬(Python) 판다스(Pandas) , openpyxl 설치
파이썬용 엑셀을 사용하기 위해서는 판다스(Pandas)라는 패키지가 필수이다. 그리고 판다스와 함께 openpyxl 패키지도 함께 설치해야 한다.
판다스에 대하여 더욱 자세히 알아보고 싶다면 아래 판다스 사이트에서 알아보도록 해라
사실 판다스는 따로 책이 있을 정도로 내용이 방대하다. 우리가 판다스의 모든 함수를 알필요는 없다. 내가 주로 사용하던 함수와 활용 방법을 기준으로 설명하겠다.
아직 판다스와 openpyxl을 설치하지 않았다면 pip로 설치부터 하자.
pip install pandas
pip install openpyxl
설치는 금방 끝이난다. 설치가 끝이 났다면 아래처럼 pandas를 import 해주자. openpyxl은 따로 import 하지 안하도 된다
import pandas as pd
이렇게 해주면 pandas를 pd라는 이름으로 사용하겠다는 의미다. 설치가 완료되었다면 본격적으로 데이터프레임을 다뤄보도록 하자.
파이썬(Python)으로 엑셀 제어하기
판다스 데이터프레임에 대하서 공부하다보면, 특히 구글링을 하다보면 데이터프레임을 처음부터 만드는 사례가 종종있다.
즉, 데이터프레임을 생성하고 데이터를 넣는것까지 직접 코드로 구현하는 사례를 종종볼 수 있다. 틀린것은 아니지만 내가 몇년간 파이썬과 데이터프레임을 다루면서 데이터프레임을 처음부터 끝까지 코드로만 구현한 경우는 찾아 보기 어렵더라.
그냥 데이터는 엑셀을 불러오면 된다. 데이터를 처음부터 코드로 넣어줄 필요가 없다. 더욱 헷갈리기만 할뿐이다.
그냥 파일 올려줄테니 다운받고, 엑셀을 읽어오면된다. 그러면 데이터프레임이 만들어진다.
샘플 엑셀 파일 다운로드 -> http://naver.me/5uIInXg4
위 링크를 클릭하면 sample.xlsx 파일을 다운받을 수 있다. 다운받기가 찝찝하면 직접 만들어도 된다.
아무튼 파일을 열어보면 아래와 같이 데이터가 들어가 있다. 데이터는 내가 연구에 활용하던 데이터인데, 데이터 자체에 큰 의미를 두지 말고 예시로만 사용하면 된다.

엑셀 파일을 열어보면 위와 같다. 가로가 행(RoW) 셀로가 열(Column) 이다. 그래서 10개의 행과 10개의 열로 이루어진 파일이다. 이것을 데이터프레임으로 만들어보겠다.
아래와 같이 코드를 입력하고 실행해보자.
import pandas as pd
df = pd.read_excel("sample.xlsx",engine="openpyxl",na_values=" ")
print(df)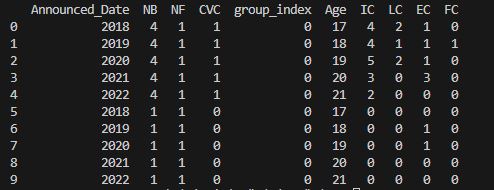
위와 같은 결과가 나올것이다. 엑셀로 보는 것과 동일하게 보여진다. (파이썬과 판다스의 버전에 따라 출력 방식이 차이가 날수 있다. 참고바란다)
import pandas as pd
df = pd.read_excel("sample.xlsx",engine="openpyxl",na_values=" ")
print(df)
print(df.shape)
위와 같이 마지막에 print(df.shape) 코드를 한줄 추가하고 실행해보자.
그럼 아래와 같이 (10 , 10) 이라고 나타난다. 이것은 row 10, col 10 이라는 의미이다. 옛날 버전에서는 데이터프레임이 출력될때 행열 개수가 나왔는데 최신버전으로 업데이트 하고나니 나타나지 않는다.

아무튼 엑셀에서의 행과 열이 모두 표현된것을 알 수 있다. 이렇게 간단하게 데이터프레임을 하나 만들 수 있으니 연습을 위해서 데이터프레임을 직접 만들고 데이터까지 코드로 삽입하도록 하지 말자. 그게 더 여렵다
판다스 데이터프레임 = 엑셀
이라고 생각하면 편하다. (내 표현이 틀렸을 수도 있으니 너무 심각하게 받아드리진 말고...)
혹시나 파일이 열리지 않거나 파일을 찾을 수 없다는 에러가 발생하는 경우가 있는데... 대게 아래와 같은 에러가 나타날 것이다.

이 에러는 작업폴더에 sample.xlsx 파일이 없는 경우에 발생한다. 보통 파이썬 파일과 엑셀파일이 같은 폴더에 있으면 해결이 된다.

파이썬 파일과 엑셀파일이 동일한 폴더에 있는지 확인해보자. 동일한 폴더에 있는데 에러가 발생하는 거라면 파일이름에 오타가 발생한 경우이다. 코드를 다시 확인해보면 된다.
아무튼 이제 코드를 설명해보겠다
df = pd.read_excel("sample.xlsx",engine="openpyxl",na_values=" ")
df는 데이터프레임 변수 이름이다. 데이터프레임의 이름을 df로 지은것이고, 이건 뭐....변수명이니 다르게 지어도 상관없는것쯤은 알것이다.
그리고 판다스의 read_excel을 통하여 sample.xlsx 파일을 읽으라는것인데, 엑셀파일을 읽는 엔진을 "openpyxl" 로 읽으란 것이다. 그래서 위에서 openpyxl 패키지를 설치한 것이고, 이것을 설치하지 않았다면 에러가 발생한다.
엑셀 파일을 다루는 방식은 여러가지가 있으나 내가 사용해본 결과 openpyxl이 가장 편했다. 뭐 사람마다 다를 수 있으니 자기가 편한것으로 읽으면 된다.
마지막으로 na_value는 결측치(빈 데이터값)가 있는 경우 어떻게 처리할 것인가를 묻는거다. 결측치는 공백으로 놔두란 의미이다.
이렇게 하면 엑셀파일의 데이터를 이용하여 데이터프레임이 만들어진다.
눈썰미가 좋은 사람들은 앞에 숫자가 붙은걸 발견했을 것이다. 이건 엑셀파일에 없던 것인데 왜 생겼을까? 라고 궁금증이 생긴 사람이 있다면 정말 눈썰미가 좋은 사람이다.

앞의 숫자는 데이터프레임의 index에 해당 되는 열이다. 공식적으로 열은 아니지만, 데이터프레임에서 저 인덱스 열을 기준으로 데이터를 처리하는 경우가 많다. 그래서 항상 인덱스가 붙어 있는데, 이 인덱스 때문에 나중에 머리가 아플때가 있다.
일단 오늘은 처음이니 그냥 인덱스가 있다는 것만 알고 넘어가자.
파이썬(Python) 판다스(Panda) 예제 및 실습
판다스를 통하여 엑셀을 불러왔으니 이제 데이터프레임을 엑셀파일로 다시 저장해보자
import pandas as pd
df = pd.read_excel("sample.xlsx",engine="openpyxl",na_values=" ")
print(df)
print(df.shape)
df.to_excel("sample2.xlsx")
앞서 작서한 코드에 마지막 한줄만 추가하면된다. 코드를 실행시키고 다시 폴더로 돌아가보자.
sample2.xlsx 파일이 생성된것을 확인할 수 있다. 이제 파일을 한번 열어보자.
데이터를 수정하지 않았으니 변경된게 없을것으로 예상했지만 새로운 열이 하나 추가되었다.
이 열은 왜 생긴것인가? 이 열이 바로 앞서 말한 index 때문이다.
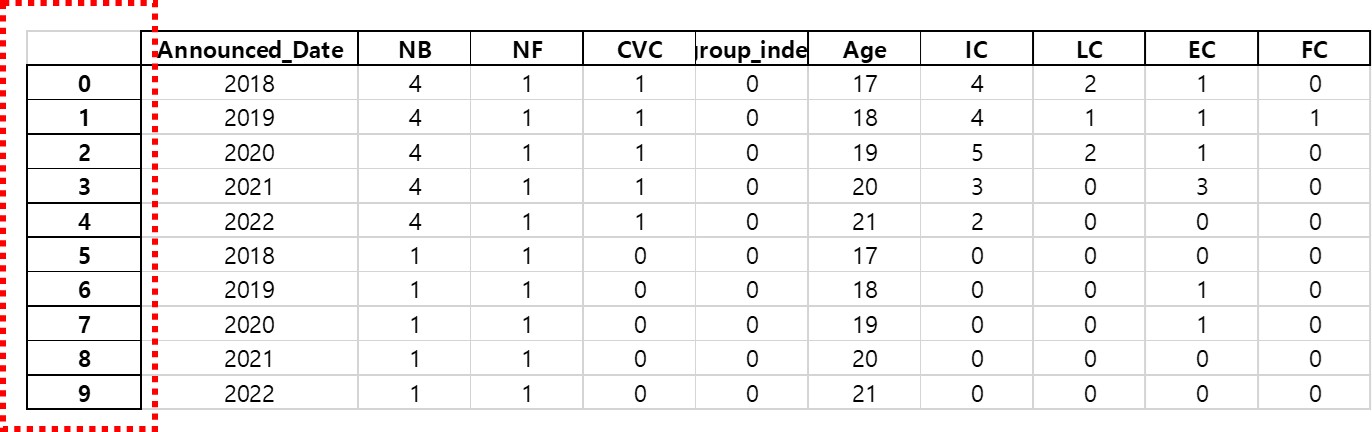
데이터프레임을 만들때 생긴 인덱스가 파일로 저장하면서 열로 포함된 것이다.
데이터프레임에서 인덱스 열은 필수이고, 인덱스 열을 지정해놓으면 편리한 경우가 있다.
갑자기 새로운 열이 생겼다고 놀라지말고 인덱스라는 점을 이해하고, 필요가 없는 경우 인덱스를 포함하지 않고 저장하는 방법도 있으니 이번에는 그냥 넘어가도록 하자.
이렇게 엑셀파일로 데이터프레임을 만들고, 데이터프레임을 다시 엑셀로 저장하는 방법을 다루었다.
이 내용이 데이터프레임을 공부할때 처음 익혀야 하는 부분이라 생각하여 데이터프레임 첫 포스팅을 이렇게 작성하였다.
데이터프레임에서 자주 사용하는 방법들을 계속 업로드 할테니 기대하시라.
'파이썬 > 파이썬 데이터프레임' 카테고리의 다른 글
| 파이썬 (Python) Dataframe 기초 강좌 #6 - iloc 누적 합 구하기 (0) | 2024.09.27 |
|---|---|
| 파이썬 (Python) Dataframe 기초 강좌 #5 - loc와 iloc 사용법과 차이점 (0) | 2024.09.26 |
| 파이썬 (Python) Dataframe 기초 강좌 #4 - 데이터프레임과 index (0) | 2024.09.19 |
| 파이썬 (Python) 데이터프레임 기초 강좌 #3 - loc와 index의 이해 (0) | 2024.09.11 |
| 파이썬 (Python) 데이터프레임 기초 강좌#2 - 행과 열, 데이터 추가하는 방법 (0) | 2024.09.08 |



