
파이썬(Python) 데이터프레임(Dataframe) iloc와 index
오늘은 데이터프레임에서 iloc와 loc의 사용법과 차이점에 대하여 이야기 해보려고 한다.
지난 시간 계속 loc에 대한 설명을 했었다. loc의 경우 인덱스가 중요하고, 이러한 인덱스를 이해해야만 loc를 사용할 수 있으므로 인덱스에 대한 이야기를 여러번에 걸쳐 포스팅을 하였다.
아마 여러분들은 loc와 인덱스에 대하여 이해를 했으리라 믿는다.
아직 헷갈린다면 다시 한번 보고 오자.
파이썬 (Python) 데이터프레임 기초 강좌 #3 - loc와 index의 이해
파이썬 (Python) 데이터프레임과 loc, index의 관계지난 시간에 다루었던 loc의 사용법이 기억나는가? 기억이 나지 않는다면 다시 한번 보고 오길 바란다.아무튼 loc 활용 방법을 기억하면서 loc를 이용
flex-link.co.kr
이제 본격적으로 iloc에 대하여 설명해보겠다.
iloc는 한마디로 말하여 눈에 보이지 않는 인덱스를 활용하는 것이다. 눈에 보이지 않는 인덱스는 또 뭐야? 라고 생각할 수 있겠지만 간단하게 엑셀을 생각해보자.
지난번 실습했던 파일을 한번 열어보자. 파일을 열어보면 index 열이 보일 것이다. 이건 우리가 만든 인덱스 열이다.

그 옆을 보자. 또 다른 숫자가 보일 것이다.

이건 바로 엑셀 프로그램에서 자동으로 할당 되는 인덱스이다. 우리가 중간에 행을 삭제하더라도 저 인덱스는 항상 오름차순으로 정렬되며 일정하게 유지된다.즉, 엑셀 프로그램에서의 기준이 되는것이라 볼 수 있다.
다시 파이썬 데이터프레임으로 돌아와보자. 데이터프레임에도 인덱스가 존재한다. 그래서 엑셀파일을 데이터프레임으로 변환할 경우 자동으로 인덱스가 생성되거나 인덱스열을 지정할 수 있음을 배웠다.
하지만 이 인덱스는 쉽게 말해 인위적으로 만든 인덱스이다. 엑셀에서 처럼 자동으로 할당되는 인덱스는 아니다.
따라서 중간 행을 삭제하더라도 인덱스는 자동으로 정렬되지 않고 중간 인덱스는 비워져 있는것을 알 수 있었다. 기억이 나지 않는다면 지난 포스팅을 보고 와라.
여기서 loc와 iloc의 차이가 나는 것이다. loc는 우리가 지정한(인위적으로 만든 인덱스)를 사용하는 것이고, iloc는 데이터프레임에서 기준으로 사용하는 자동할당 되는 인덱스를 사용하는 것이라 생각하면 된다.
다만 엑셀과 차이가 나는 것은 시작이 1이 아니라 0에서 시작한다는 점이다.
파이썬(Python) 데이터프레임(Dataframe) loc와 iloc의 사용법
sample4.xlsx 파일을 데이터프레임으로 열어보자.
import pandas as pd
df = pd.read_excel("sample4.xlsx", engine="openpyxl", na_values= " ", index_col=0)
print(df)

즉 우리가 엑셀의 첫번째 열(0번 열)을 인덱스로 지정하였기때문에 데이터프레임에서도 인덱스로 지정된 것을 알수 있다.
이렇게 지정된 인덱스는 자동으로 정렬되지 않기때문에 필요시 정렬 명령을 따로 해주어야 한다.
이 인덱스를 이용하는게 loc 이다.
그럼 데이터프레임에서 자동 할당되는 인덱스 어디서 볼 수 있는가? 사실 볼 수 없다. 엑셀처럼 보이지 않기때문에 그냥 있다고 생각해야 한다.

이 인덱스는 중간에 행을 삭제하더라도 자동으로 정렬이 되는것이다.
이 눈에보이지 않는 인덱스, 데이터프레임의 기준이 되는 인덱스를 활용하는 것이 바로 iloc이다.
그러면 이제 iloc를 활용하여 데이터에 접근하고 수정을 해보도록 하자.
iloc는 행과 열 모두 인덱스로 접근해야 한다. 예를 들어 index가 0인 행을 데이터에 접근해보자.

index가 0인 행열의 Age 값은 17이다. 이 값을 20으로 변경해보자.
먼저 loc로 접근 한다면 이렇게 해야 할 것이다.
import pandas as pd
df = pd.read_excel("sample4.xlsx", engine="openpyxl", na_values= " ", index_col=0)
df.loc[0, 'Age'] = 20
print(df)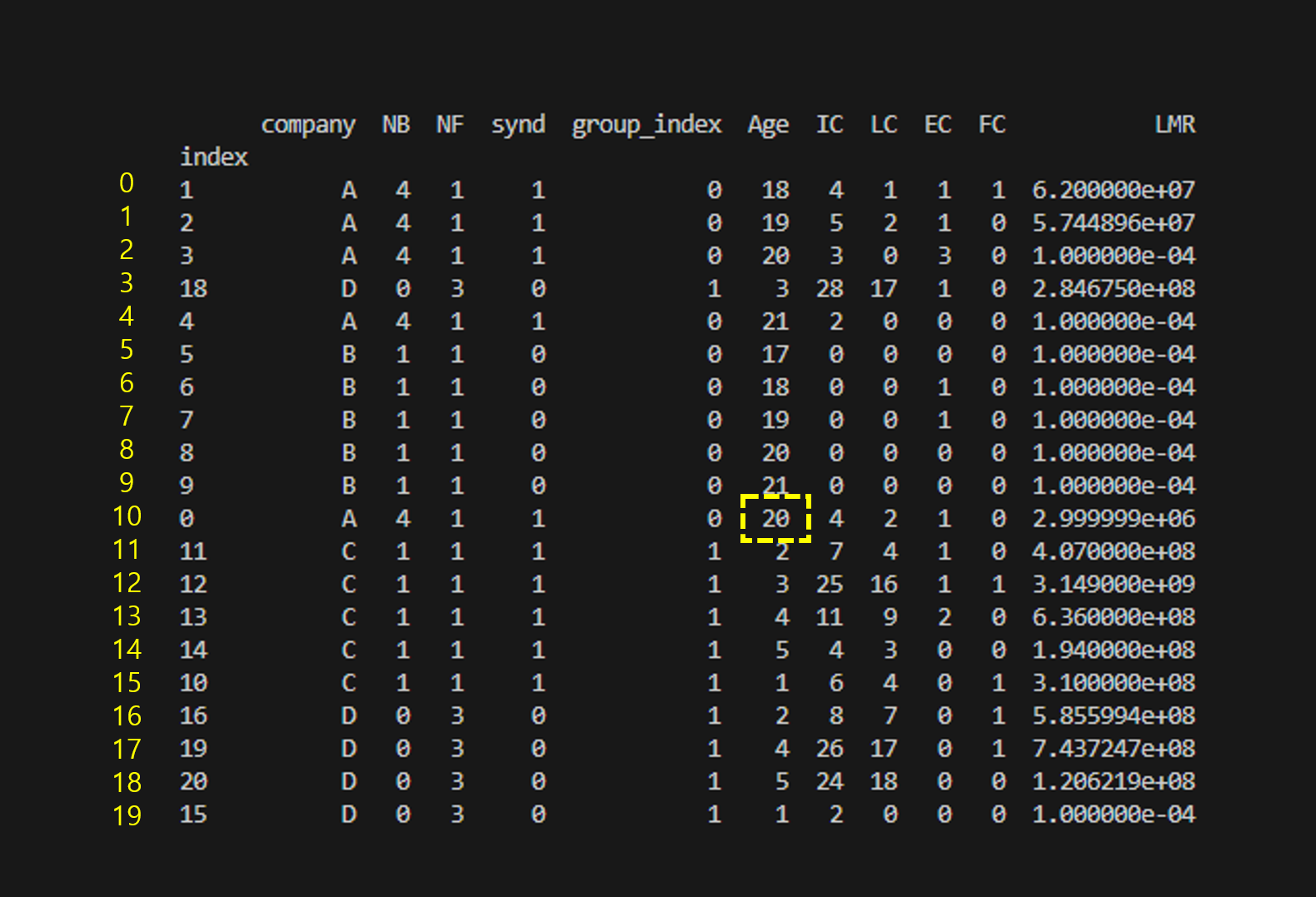
loc의 경우 우리가 지정한 index의 값을 기준으로 접근한다. 열을 접근할때도 열 이름으로 접근을 해야 한다.
그래서 df.loc[0, 'Age'] 식으로 접근을 하였다.
하지만 iloc는 값이 아니라 인덱스 번호로만 접근해야 한다. 이번에는 iloc로 값을 변경해보겠다.
값을 변경하기 위해서는 행의 인덱스 번호와 열의 인덱스 번호를 알아야 한다.
행의 경우 10이고 열의 경우 5이다. 열의 인덱스 번호를 알기 위해서는 df.info()를 통하여 확인 할 수 있다.
import pandas as pd
df = pd.read_excel("sample4.xlsx", engine="openpyxl", na_values= " ", index_col=0)
print(df.info())

이렇게 열의 인덱스 번호를 알았으니 값을 20으로 변경해보자.
import pandas as pd
df = pd.read_excel("sample4.xlsx", engine="openpyxl", na_values= " ", index_col=0)
df.iloc[10, 5] = 20
print(df)
위 코드를 실행시키면 동일 한 결과가 나타나는 것을 알 수 있다.
파이썬(Python) 데이터프레임(Dataframe) loc와 iloc의 차이점
아직 긴가 민가 할 수 있다. 다른 예제로 다시한번 비교해보자.
위 파일을 열어봐라. 데이터는 동일한데 인덱스가 숫자가 아니라 문자로 되어 있다.

이렇게 되어 있는 데이터라면 확실히 이해가 될 것이다.
이제 loc와 iloc로 각각 다른 값을 변경해 보겠다.
import pandas as pd
df = pd.read_excel("sample4-1.xlsx", engine="openpyxl", na_values= " ", index_col=0)
df.loc['f','Age'] = "loc로 변경"
df.iloc[12,5] = "iloc로 변경"
print(df)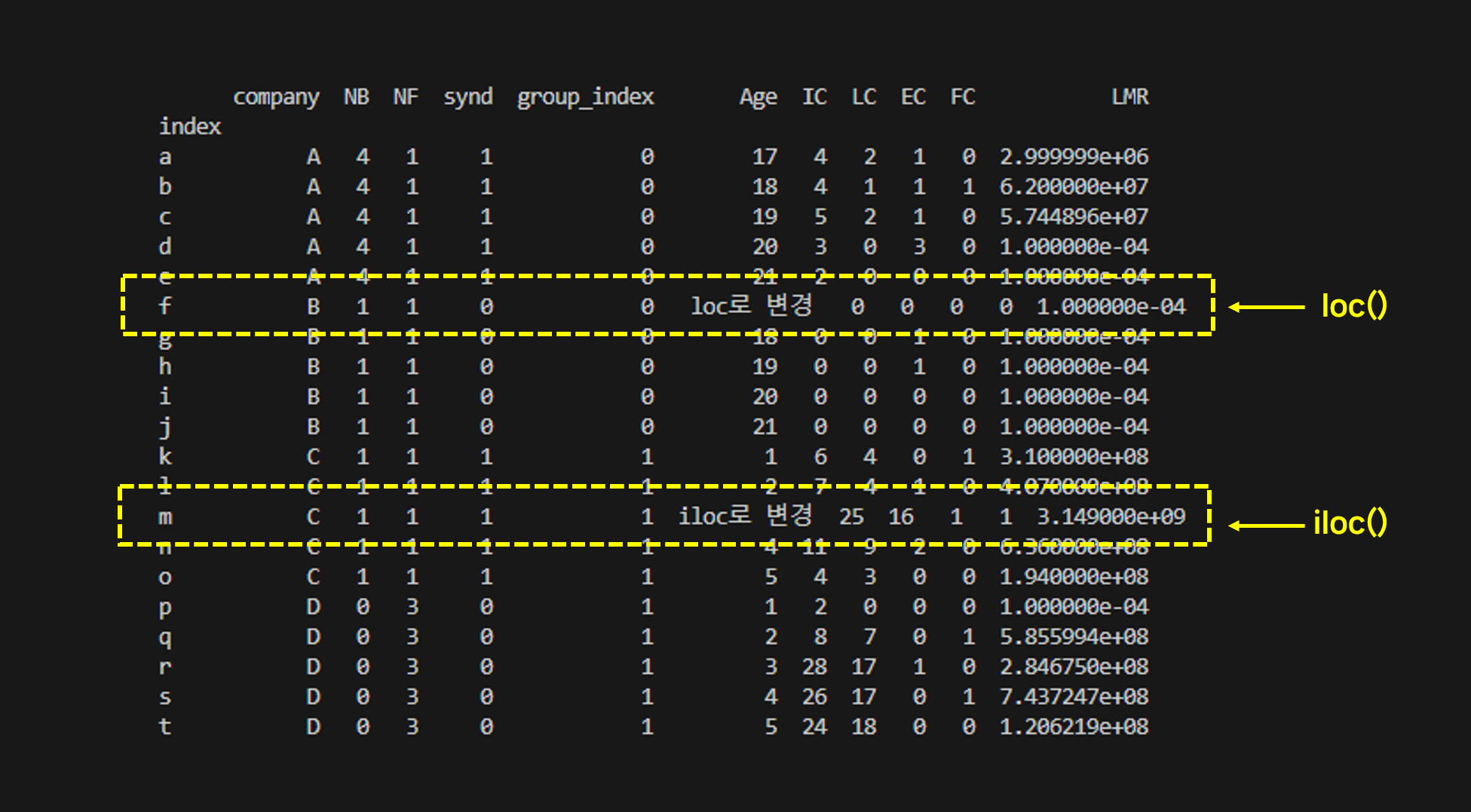
loc와 iloc의 차이를 확실히 알겠는가?


마무리
loc와 iloc는 많이 사용하면서 많이 헷갈린다.
어떤걸 사용하는 것이 좋을까? 데이터마다 다르다. for 문을 통하여 데이터에 접근하고자 할때 iloc가 편하다.
다음행으로 넘어가거나 다음 열로 넘어갈때 간단하게 연산만으로 가능하기 때문이다.
하지만 직관적이지 않고 나중에 코드를 보게 되면 저게 어떤 행인지, 열인지 확인이 어렵기 때문이다.
아무튼 이 정도면 확실한 이해가 되었으리라 생각된다. 사실 이렇게 자세하게 설명해주는 곳은 잘 없지 않나??
나름 쉽게 설명한다고 했는데 이해가 되었길 바란다.
'파이썬 > 파이썬 데이터프레임' 카테고리의 다른 글
| 파이썬 (Python) 데이터프레임 기초 강좌 #7 특정 다중 조건 행 추출 (0) | 2024.09.28 |
|---|---|
| 파이썬 (Python) Dataframe 기초 강좌 #6 - iloc 누적 합 구하기 (0) | 2024.09.27 |
| 파이썬 (Python) Dataframe 기초 강좌 #4 - 데이터프레임과 index (0) | 2024.09.19 |
| 파이썬 (Python) 데이터프레임 기초 강좌 #3 - loc와 index의 이해 (0) | 2024.09.11 |
| 파이썬 (Python) 데이터프레임 기초 강좌#2 - 행과 열, 데이터 추가하는 방법 (0) | 2024.09.08 |



